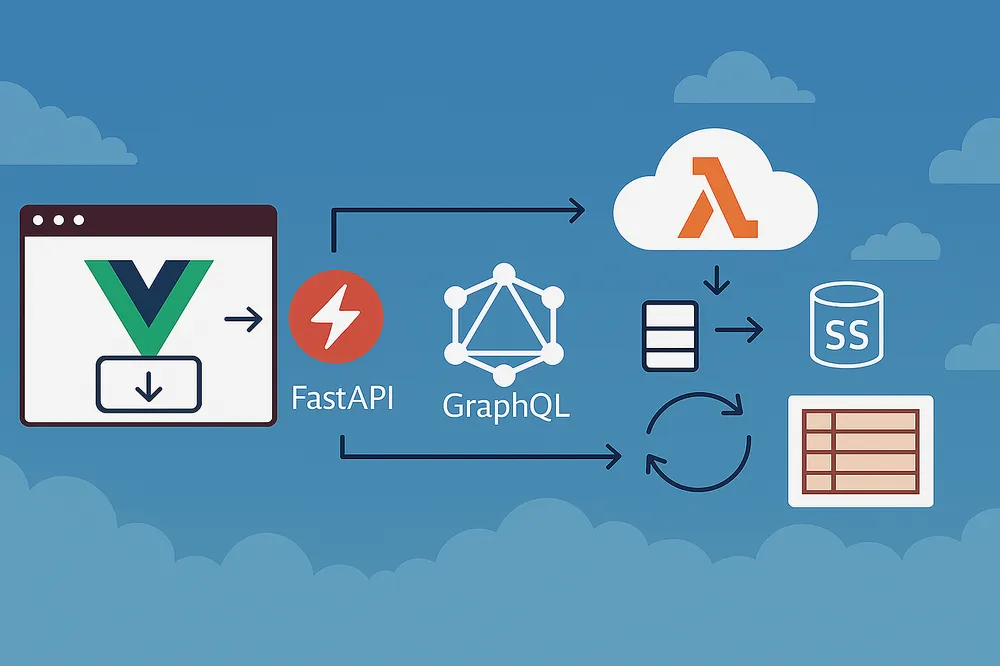
What is a data warehouse?
Data warehouses are enormous storage facilities for data collected from a variety of sources. It's an abstracted representation of the company's operations, arranged by subject. It has undergone a lot of transformation and has a lot of structure. Data isn't entered into the data warehouse until its purpose is determined. Data that is organized, filtered, and has been processed before for a clear objective is stored in a Data warehouse.
Why should startups choose a data warehouse?
Decisions are made based on a set of data. Data is processed, analyzed, and then the decision part of the process takes place. Data warehouses show significant differences from operational databases in the sense that they hold past data, allowing corporate leaders to study data over a prolonged period of time. Your startup needs a data warehouse because:
1. They ensure consistency:
Data warehouses are storage spaces programmed in a way that eases your work. They apply a standard format to all the data collected and makes it easier for the employees to analyze this structured data and share insights with the team later.
2. They will help make better decisions:
Understanding the trends and patterns of the market is important. Decisions need to be based on facts and that is exactly where data warehouses come in. They increase the speed and accuracy with which multiple data sets can be accessed, making it easier for business decisions to extract insights that help them develop market strategy that would set them apart from their peers.
3. Maximises Efficiency:
Data warehouses allow leaders to access the data that helps them understand the pattern and make future strategies. Understanding what has worked in the past and how effective their previous methods have been really saves time and is effective.
How do data warehouses benefit startups?
If you are planning on starting a software startup and are worried about data storing options, then a data warehouse would make for a great choice. Data warehouses are capable of delivering enhanced business intelligence, improve the quality of data, maintain consistency, save time, generate a high run on investment (ROI), enable organizations to forecast confidently, improve the decision-making process, and provide competitive advantage. These are some of the ways data warehouses can prove to be beneficial for your business.
Can a data warehouse replace a data lake?
A data lake is not a replacement for a data warehouse. As mentioned above, these terms cannot be used interchangeably. There are significant differences between the two. Some of these differences include:
1. Structure of the data:
Raw data is data in its original form. It has not been processed for any purpose yet. One of the major differences between data lakes and data warehouses is the structure of data stored. Data warehouse generally stores data that has been processed, about the needs of a clear objective or specific goals whereas data lake stores data in raw form, which is unprocessed data. This is one reason why data lakes require a much larger storage capacity than data warehouses. Data that has not been processed is pliable and may be readily evaluated for any purpose, making it perfect for machine learning. Moreover, with so much raw data, data lakes can easily become data swamps if proper data quality and control mechanisms aren't in place.
2. Purpose:
The purpose of data stored in data lakes is undetermined. They may be used in the future for a specific purpose but till then we just have floating raw data that is taking up storage space. On the other hand, if we talk about data warehouses, the data stored there is structured and filtered according to the needs of a particular objective. This means that the space used by that data is never going to be wasted as this data will surely be used. However, one cannot say the same for data stored in data lakes.
3. Processing:
Data warehouse needs structured and organized data. You must filter and alter the data before entering it into a data warehouse. Frequently, you'll need to represent it as a star or snowflake schema, which adheres to the schema-on-read principle (SQL). If we talk about data lakes, you don’t have to process the data here as any and every form of data can be stored in data lakes. When you're prepared to use the data, you can use schema-on-write to give it the required shape and structure.
4. Security:
The data lake will contain essential and frequently extremely sensitive company data as big and growing volumes of different data are poured into it. Hence, the security of the data becomes a major concern. Data warehouses are more established and reliable than data lakes. Advanced technologies, which include data lakes, are still in their infancy. As a result, the capacity to secure data in a data lake becomes immature. Unlike advanced technologies, data warehouse advancements have been here and in use for decades.
5. Insights and Users:
Since data lakes contain all forms of data and allow users to access data before it has been processed, cleansed, or structured, they can get to their results faster than with a standard data warehouse. Those inexperienced with raw data may find it challenging to navigate data lakes. To comprehend and translate raw, unstructured information for any unique business use, a data scientist and specialized tools are usually required. Data scientists are now using data lakes. We can locate structured data in a data warehouse that is straightforward to navigate for business professionals. Processed data, such as that found in data warehouses, just needs that the user is knowledgeable about the subject matter.
Conclusion:
A data warehouse is a centralised collection of data that can be studied to help people make better decisions. Moving beyond conventional databases and into the world of data warehousing can help organisations get more out of their analytics initiatives.